语音识别技术要经历两个阶段
- 语音识别
- 2024-04-14 18:17:03
- 2438
语音识别技术是一种允许计算机处理和理解人类语音的先进技术。 它涉及两个主要阶段:
1. 语音到文本 (STT)
语音到文本阶段涉及将人类语音转换为文本。 它使用声学模型和语言模型:
声学模型:分析语音信号以识别发音和单词的声学特征。
语言模型:预测基于上下文的单词序列的可能性,帮助识别单词边界和含义。
STT 系统通过对大量语音和文本数据的训练来创建这些模型。 它们能够处理各种口音、说话方式和噪声水平,从而产生准确的文本转录。
2. 自然语言理解 (NLU)
自然语言理解阶段涉及理解文本的含义。 它使用自然语言处理 (NLP) 技术,例如:
语法分析:识别句子中的词性、词组和语法结构。
语义分析:确定单词和短语的意义和意图。
话语分析:理解文本中不同句子的关系和连接性。
NLU 系统将文本转录翻译成结构化数据,使计算机能够提取信息、回答问题并执行基于自然语言的交互。 它们还可以识别语音中的情绪、意图和情感。
通过这两个阶段,语音识别技术能够让计算机有效地理解和处理人类语音,从而在广泛的应用中提供自然和无缝的交互体验。
上一篇:语音识别技术框架阶段顺序是什么
下一篇:语音识别的基本原理

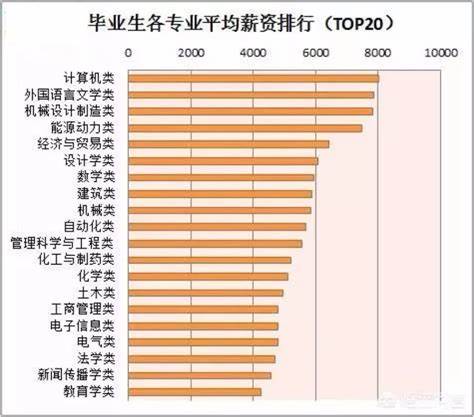
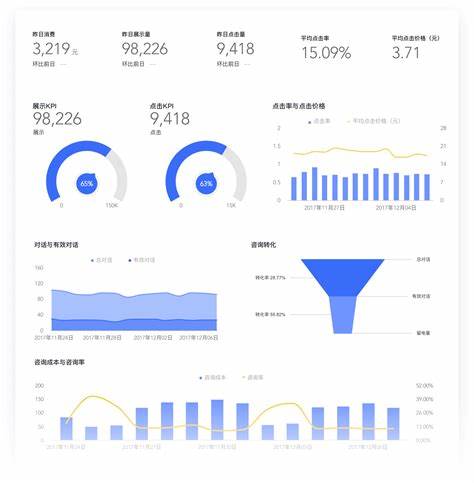
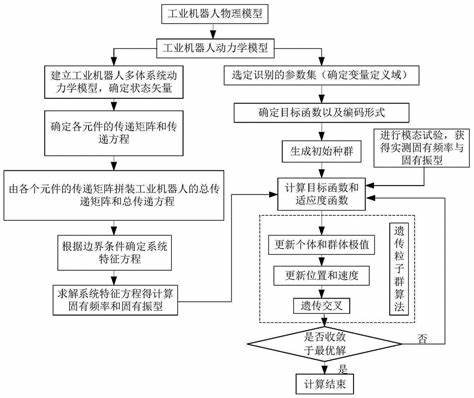



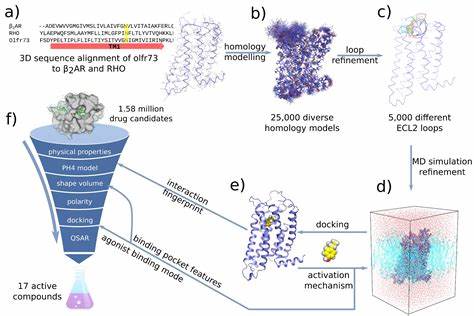



热门文章
自动化框架包括哪些
2024-04-14 17:21:54
自动化运维平台是什么
2024-04-14 17:21:49
全自动化配件价格表
2024-04-14 17:15:56
机械制造及自动化论文
2024-04-14 17:15:41
非标自动化电气控制原理
2024-04-14 17:14:33
人工智能能代替的工作
2024-04-14 17:10:04
电气工程及其自动化专业为几大类
2024-04-14 17:09:03
数据分析师会招小白吗
2024-04-14 17:07:16
自动化属于计算机大类吗
2024-04-14 17:04:33
人工智能未来发展阶段
2024-04-14 17:04:31